Did you know that you can navigate the posts by swiping left and right?
인공지능 정리
12 Mar 2020
. category:
tech
.
Comments
#mechatronics
#AI
#hunkim
#pytorch
Training data set이란
ML이라는 블록이 있다고 가정하고 답이 정해진(label이 정해진) X의 입력과 Y의 출력을 학습한다하면 학습을 한 label이 Training data이고 이 학습을 통해 ML의 모델이 만들어진다. 그러면 이후에 임의로 정한 X값을 넣어주면 ML이 예상된 Y값을 출력해주게 된다.
Supervised Learning의 유형 대개 3가지로 나눌 수 있다.
1.Regression
2.binary classification
3.multi-label classification
Linear Regression이란
우선 Training data는 그래프로 그려보면 선형으로 그려지는데
예를들어 공부를 많이할수록 성적이 오른다.와 같이 많은 가정들을 linear regression으로 표현할 수 있고
수식은 H(x) = Wx +b로 가설을 세울 수 있고 이 수식을 통해 그려진 선중에 무엇이 가장 적합한 선일까?를 알아야한다.
알아낼 수 있는 방법은 실제 데이터와 H(x)와 얼마큼 차이가 있는가에 따라 구별할 수 있다.
H(x) - y로 표현할 수 있다. 하지만 실제로 Cost function(Loss)는 (H(x)-y)^2으로 표현해 차이에 더 무게를 두게 된다.
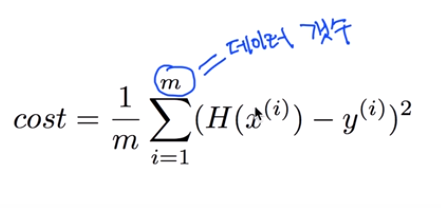
Linear Regression의 Cost 최소화 알고리즘
cost를 최소화 : 즉 Loss를 최소화해야함 그래야 내가 원하는 실제 값과 같은 값을 얻는 모델을 얻을 수 있기 때문이다.
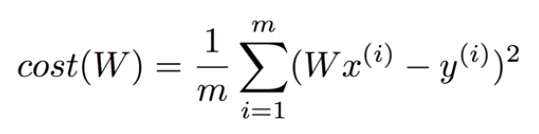 최소화를 위한 Gradient algorithm을 설명하면
비교를 하면서 미분한 값으로 조금씩 값을 찾아가는 방식이다.
최소화를 위한 Gradient algorithm을 설명하면
비교를 하면서 미분한 값으로 조금씩 값을 찾아가는 방식이다.
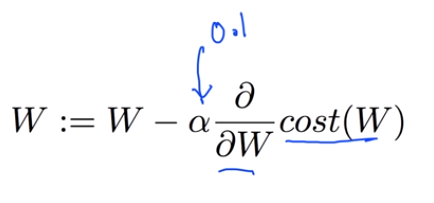 gradient algorithm을 실제로 미분해보면 다음과 같다.
gradient algorithm을 실제로 미분해보면 다음과 같다.
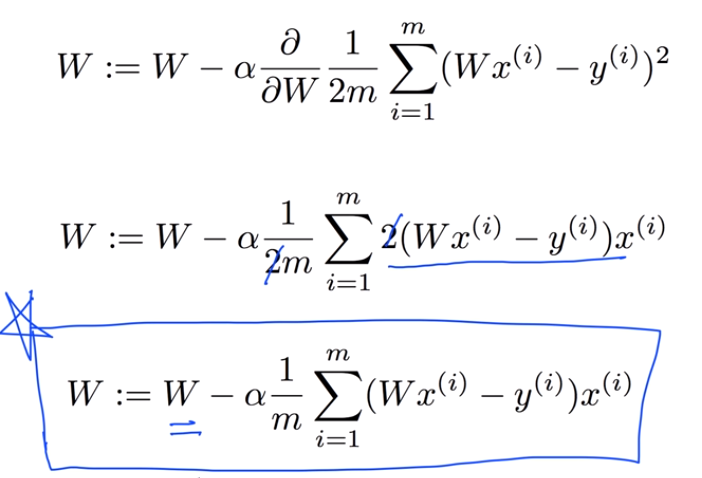
Multi-variable linear regression일 때
H(x)와 Cost function은 어떻게 될까?
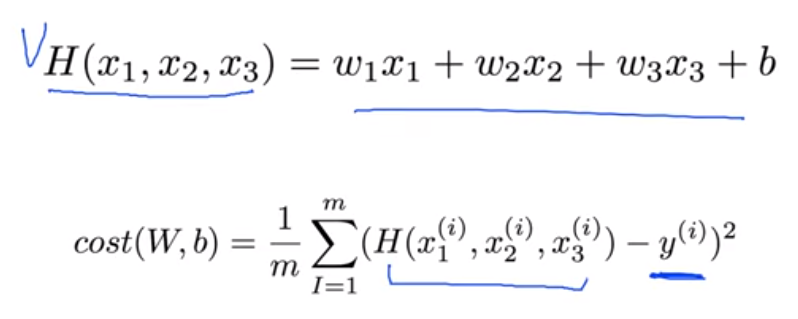 Matrix를 이용한 H(x) 표현은
H(X) = XW로 표현할 수 있다.
Matrix를 이용한 H(x) 표현은
H(X) = XW로 표현할 수 있다.
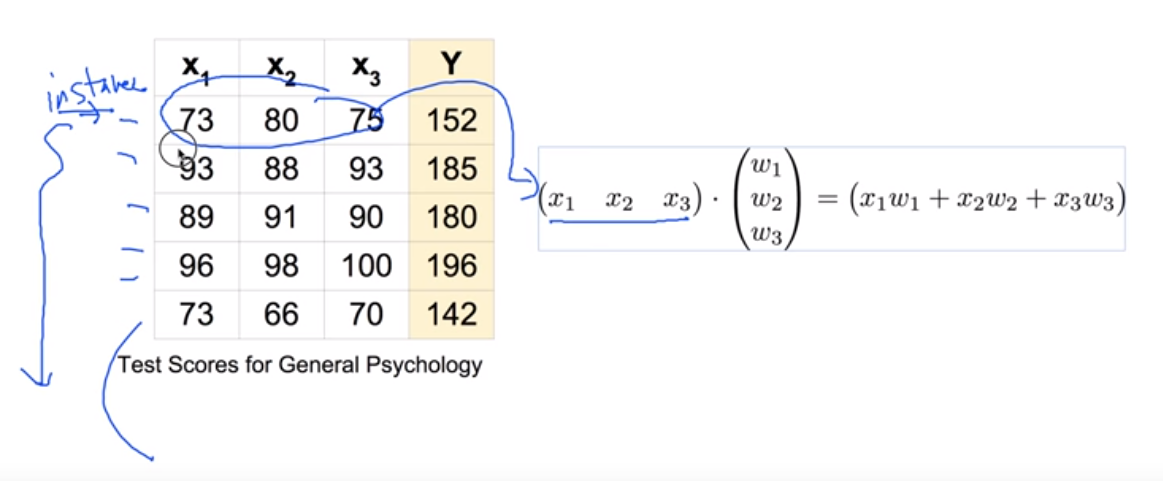
위의 입력 변수x와 출력 변수 y에 대해 weight를 곱한 식으로 matrix를 정리하면 다음과 같다.
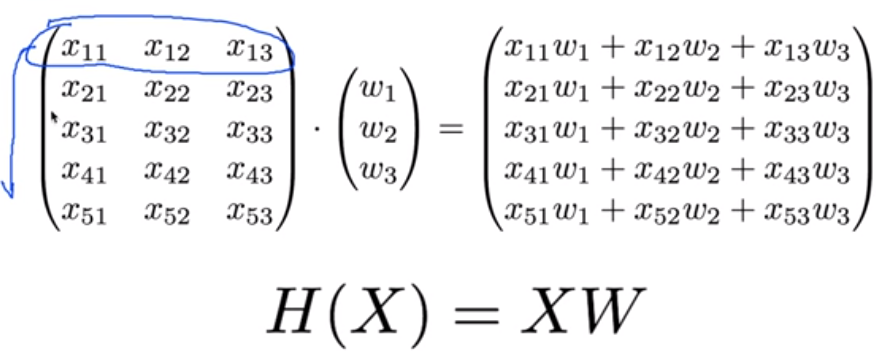
Logistic Classification의 정의
예를들어 시험 pass, fail을 예측하는 시스템이 있다고 했을 때 input의 값이 보편적인 값보다 상당히 차이나는 값으로 training data로 들어오게 된다면 pass, fail의 예측이 불명확해질 수 있다. 이 문제를 해결하기 위해 나온 방법이 sigmoid라는 것인데
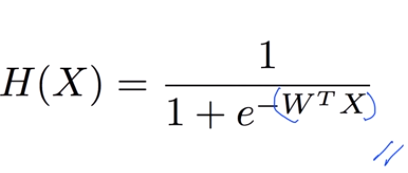
Logistic Regression의 cost 함수 정의
H(X)가 위 그림처럼 표현되어 울퉁불퉁한 그래프를 가지게 된다.
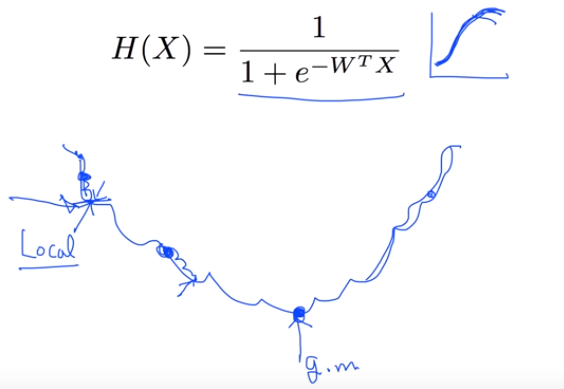 그래서 위 그림과 같은 문제의 이유로 새로운 cost function의 형태를 만들었는데
그래서 위 그림과 같은 문제의 이유로 새로운 cost function의 형태를 만들었는데
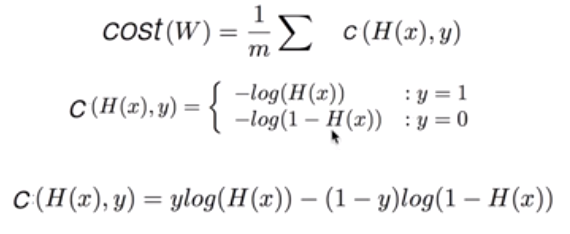 cost function은 다음과 같이 다시 정리할 수 있고 이를 다시 gradient방법을 통해 최적화를 하게 된다.
cost function은 다음과 같이 다시 정리할 수 있고 이를 다시 gradient방법을 통해 최적화를 하게 된다.
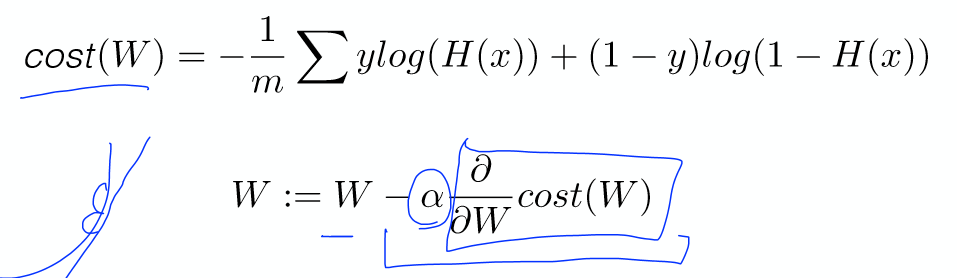
Logistic regression은 우리가 단순히 Hypothesis를 H(x) = Wx로 식으로
세우면 0또는 1이 아닌 값이 나올수 있어서 Z = H(x), g(z)식으로 놓고
sigmoid 함수로 둠으로써 0과 1내의 값으로 결과가 나오도록 하게된다.
Multinomial classification을 정의해보면
단순히 0과 1로써 구분하는 것을 넘어, 다양한 것으로 분류하는 것이다.

3개의 종류를 구별하는 것이므로 3개의 선을 그리게 되는데 행렬로 표현하게 되면 y hat 값들은 도식화된 그림에서의 z에 대응되는 데이터이므로 각각의 y hat에 sigmoid 함수를 적용하게 된다.
학습을 할때 learning rate를 정해주는데 우리가 gredient descent로 값을 찾아갈 때 사용하는 기울기 값이라고 생각하면 된다.
근데 이 learning rate에 관해서 여러가지 문제가 있는데
우선 값이 너무 크게되면(Large learning rate)

이와 반대로 값이 너무 작으면(small learning rate)
 이러한 문제가 발생하게 되어 우선 cost function을 확인하면서 시도해봐야한다.
이러한 문제가 발생하게 되어 우선 cost function을 확인하면서 시도해봐야한다.
평균과 분산을 가지고 normalization(Standardization)을 할 수 있고
overfitting의 문제가 발생했을 때 training data가 많거나 feature의 수를 줄이거나 regularization을 함으로 줄일 수 있다.
Regularization을 이용하면 weight를 좀 적은 값으로 놓자라는 개념인데

자료지식은 Youtube에 올라와 있는 Sung Kim님의 자료에서 배울 수 있었습니다.

github를 이용해 만들어본 블로그입니다.